wordpressハッキングされました(涙)adminアカウント消すだけじゃダメ!
とある非営利団体のweb masterになって3日目。
wordpressで作った新サイトがハッキングされました(涙目)
私が作ったサイトではなく、ちょっとセキュリティが甘かったので、管理をひきついですぐに、とりあえずadminアカウントは消したのだけど、簡単に破られました。
理由は、新しく作ったアカウントのニックネーム(web表示名)が、ログインアカウントと同じだったから(爆)
wordpressは、デフォルトで「投稿者名」のページを作ります。同じ投稿者が投稿した記事を集めるページです。
で、ここに表示されるニックネームが、ログインで使うログインアカウントと同じだと、外部にログインアカウントを公表しているのと同じことに!
私もうっかりして、ニックネームを変えるのを忘れていたんですが、コレ、ひとこと注意書きがあってもいいよね……(汗)
ただ、今回のハック、なんかちょっとへんな感じで、新しく作ったアカウントのログイン名がまたadminに書き直されていたんです。(ニックネームじゃなくてログイン名の方)
こんなの、ロボットプログラムには多分できないんじゃないかと思うんだけど、詳しい方、どうなんでしょうね?
アカウントは、私が新しく作ったアカウントしかありませんでした。
手動でこれをやるなら、
1)新しく作ったアカウント(例題として、たとえばdummyadminとかにしときます)のログイン名を、「投稿者」のページで収集、これにパスワードクラッキングのプログラムをしかけてパスワードを取得
2)クラックしたdummyadminでログイン、新たにadminアカウントを作成
3)作成したadminアカウントでログイン、dummyadminを削除し、adminアカウントのニックネームをdummyadminに変更
という形で可能なのだけど、これを自動でやる方法なんてあるのかしら。
最悪の事態は、サーバー上に悪意のあるユーザーがいて、データベースを直接いじられた、というケースですが……。
そうでないなら、うちのwebを狙って手動でハックされたことになるので、これもかなりいやーな感じです。
それとも、最近のハッカーは手動でちまちまハックするのもアリなのか??
まあ、受け継いだパスワードも辞書に乗ってる文字+数字という、いかにもクラックしてください、といわんばかりのものだったんですが(汗)
(さっさと変えればよかった)
当然、パスワードも変えられてしまっていたのでログインできず、myphpadminでwp_userテーブルにアクセスし、ログイン名とパスワードを強制変更という荒技を使ってログインしました(しかもパスワードは暗号化されているから、他に個人で運営しているwordpressにダミーアカウントを作り、そのパスワードをmyphpadminで見てコピー&ペースト)。
それにしても、ある程度アクセス数のあるサイトのセキュリティ対策がどれほど大事か、ホント思い知りました。
個人のブログなんかとは比べ物にならないですね。
私もwpのサイトを他に3つ、何年も管理していますが、いままでこんなことは一度もありませんでした。
その非営利団体の新サイトは、お披露目してから、1ヶ月くらいだったと思います。まあ、非営利団体のウェブページなんてのは、クラッカーにとっていいターゲットなのかもしれないですが……
(それなりに閲覧者数があって、しかも大抵人手不足でwebのセキュリティまで手がまわっていない)
以下、今回導入した対策です。
1)ログイン名、ニックネームの設定と、adminアカウントの削除
ログイン名とニックネーム(及びブログでの表示名)は必ず違うものにする。
要するに、ログイン名が見えるところに書かれてはいけない。
(実は、これをやっても、ある作業をやるとURLからログイン名が割れてしまうのだけど、現状これをWP側の設定で回避するにはそれ用のプラグインが必要な模様です。とりあえず、ログイン名を隠すより強いパスワードを作る事の方が効果があるので、検索に簡単に引っかかってしまう場所にログイン名が出ないようにしておく。)
2)パスワードの設定
ログインが毎回面倒になるけど、ランダムジェネレータで作る。
最低8文字、記号、数字、大文字、小文字を混ぜる。
こちらのページで作らせていただきました。
http://tomari.org/main/java/password.html
(紛らわしい文字を使わない設定にできるのが有り難い)
3)ファイルのパーミッション変更
.htaccess --- 644 から 604 へ
wp-config.php -- 664 から 404 へ
これは、同じサーバに悪意があるユーザがいる場合の対策です。
グループビットにパーミッションがあると、簡単に設定ファイルを読み書きできてしまうことがあります。実は、これが一番怖いパターンで、今回のクラッキングがそうでないことを祈ってるんですが……
今回の対策で、web上からのアタックに関してはほぼ足跡を残さずにやるのは不可能になりましたので、これでまたのっとられたらこのケースの可能性が高い。
4)ログインの回数制限をするプラグインを入れる。
とりあえず、Simple Login lockdownを入れました。
5回間違うと、1時間はログインできない。
あんまり複雑なプラグイン入れても管理しきれないので。
5)Crazy Bone プラグインを入れる。
ログイン履歴を保存してくれるプラグインです。
クラッカーがどんなログイン名とパスワードの組みでトライしたか、IPアドレスを保存してくれます。
勿論正規のログインも記録されるので、「こんなところからログインした覚えない!!」なんてことがあったら、既にパスワード破られている証拠です……。
正直、一度管理パスワード破られたら、証拠隠滅は簡単なので、ホントはサーバーサイドでやった方がいい気もしますが、このサイトが入ってるサーバ、ログインシェルもないしあんまり自由がきかないので、面倒になって入れました。
6)wordpressは最新のものを!!
3.6.1にしろ、とあちらこちらから警告があったので、なんかよほどひどいセキュリティーホールがあったか??
同じ対策を、私が運営している他のサイトにも入れときました。
xrea, coreserverなどは、いろいろ制限が厳しいため、設定をしないと、たとえばwpの管理画面からテンプレートを書き換えるなどはできません。
実は既にパスワード破られてるんだけど、テンプレの書き換えができなかったためハッカーが何もせずに帰った、ってケースもあるかもしれないですね。
ログイン履歴はとっておいた方がいいです。
それにしても、トップページのっとられるとほんとムカツクな〜!
C++ std::mapでconstがどうの、と怒られる件
ものすごく初歩的な話なのだけど、久々にハマった(しかも2度目)ので忘れないよう記録。
std::mapで、コンパイル時にこういう怒られ方したことないですか?
error: passing 'const std::map
....の部分は面倒なのではしょってしまいましたが。
何をやって怒られたかというと、こんな感じのコードです。
class MyClass { double weightA_; double weightB_; void RestoreWeight(const std::map<std::string, double> &wmap) { weightA_ = wmap["A"]; weightB_ = wmap["B"]; } };
何がイカンかというと、mapのオペレータはconstがついてるmapには使えない、ということです。
ちょっと考えれば当たり前で、mapのオペレータというのは、引数で与えるキーに対応するエントリがない場合、そのキーのためのエントリを作るんだから、const functionになりようがないんですよね。
でも、個人的には、const 戻り値 operator[](キー)const みたいなのも存在してそうな気がしてしまうので、こういう失敗をする、と……。
というわけで、上の例は、このように書くしかなさそう。
class MyClass { double weightA_; double weightB_; double GetValue(const std::map<std::string, double> &wmap, const std::string &key) { std::map<std::string, double>::const_iterator i = wmap.find(key); if (i == map.end()) return 1.0; // default weight return i->second; } void RestoreWeight(const std::map<std::string, double> &wmap) { weightA_ = GetValue(wmap, "A"); weightB_ = GetValue(wmap, "B"); } };
constは正直うざいけど、上の怒られるコードが許されたら多分計算結果は怪しいことになるので、こういうときC++比較的安全だな、と思う。。
追記。
上記GetValue関数をテンプレートにして、どこでも使えるようにしようとしてハマった。
#include <map> namespace Utils { template <class X, class Y> const Y &GetMapValue(const std::map<X,Y> &m, X x) const { std::map<X,Y>::const_iterator i = m.find(x); if (i == m.end()) { log_error("Failed to extract map value."); } return i->second; } }
これをコンパイルすると、こんな感じで怒られます。
error: expected ‘;’ before ‘i’
なんで';'が必要やねん、とえらくハマったら、要するに、std::map
というわけで、その行を
typename std::map<X,Y>::const_iterator i = m.find(x);
としたら、とりあえずコンパイルは通った。これでまともに動くかは現在テスト中。
WP-DBManager + MAMPでサイトのフルバックアップをとる方法2 : coreserver へのリストア
この記事は、WP-DBManager + MAMPでサイトのフルバックアップをとる方法の続きです。
WP-DBManager + MAMPでローカルに保存したサイトのフルバックアップをどうやってリモートサーバにリストアするか。
うちはcoreserverを使っているので、coreserverの場合の例題です。
多分xreaでも同じだと思います。
1)coreserverの管理画面にログインし、データベースの保存(バックアップ)をする
これ、大変重要です!!!
というのは、まったく予期しなかった事態が起きたためで、偶然直前にバックアップをとってなかったら、wpのテーブルひとつ消し飛んだところでした……。
まず、データベースのページに行きます。すると、こんな感じで、作ってあるテーブルが見えるはずです。
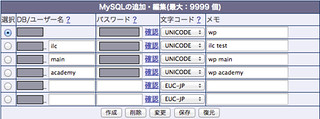
最初にやることは、この見えているテーブルを全部バックアップすることです。ひとつひとつ、「選択」にチェックを入れて、「保存」ボタンを押す、を繰り返します。
反映には数分かかるので、ちゃんとリモートのホームディレクトリにデータベースの数分のバックアップファイル(mysql.dump, mysql_main.dumpなどの名前になっているはず)が出来ているかを確認して下さい。
2)リストアしたいテーブルを削除&再度作成
次に、ローカルに保存してあるWP-DBManagerのバックアップデータベースで置き換えたいテーブルを削除します。
今回は、1番上にリストされているテーブル(メモ欄にwpと書いてあるやつ)を削除します。
「選択」にチェックを入れ、「削除」ボタンを押すと……
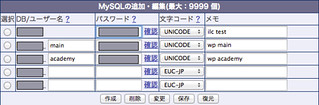
げげっ!! 2番目にリストされていたデータベースの名前が勝手に繰り上がってる!!
ちなみに、この状態で、1番目のデータベースは存在していません。リストにはあっても、今削除しちゃったから、登録されていないのです。これは、リモートにログインしてmysqlコマンドをたたいてみると、確かに存在していないのがわかります。
というわけで、何故か消えたテーブル(図ではilc testとコメントが入ってるテーブル)はとりあえず後でリストアすることにして、まずは消した1番目のデータベースを再度作成します。
1番目のデータベースの「選択」をチェックし、「作成」ボタンをクリック。
すると、新しくテーブルが生成されます。
さっき何故か消えちゃった2番目のデータベースも復活しないかな、と淡い望みを抱いたのですが、やっぱり復活しないらしい。
仕方がないので、ilcのテーブルも作り直します。
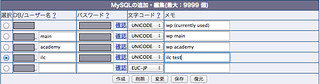
これで、「作成」を押し、そのあと「復元」を押せばOK。
3)WP-DBManagerのバックアップファイルを作成したテーブルに流し込む
まず、WP-DBManagerのバックアップファイル(1378870121_-_xxxxxx.sqlとかいう名前)をcoreserverの自分のホームディレクトリにアップロードします。public_htmlの下ではなく、FTPソフトなんかでは一番上の階層になる場所です。
それから、1378870121_-_xxxxxx.sql を<データベース名>.dumpにリネームします。さっきとったバックアップファイルもとっておきたい人は、先刻とったバックアップファイルのファイル名の語尾に.bakとか適当につけて、名前が競合しないようにして下さい。<データベース名>.dumpという名前のファイルでないと、管理画面からはリストアできません。DB/ユーザー名がたとえばabcだったら、abc.dumpです。
名前の変更が済んだら、データベース名の横の「選択」ボタンをチェックし、「復元」を押します。
これで、3分ほど待てば、データベースにバックアップしたファイルの内容が読み込まれます。
4)ローカルにとっておいたwpディレクトリをリモートにアップロードする。
アップロードする場所は、もともとwpディレクトリのあった位置です。この位置以外においても、正しく作動しません。
更に、ローカルで加えた変更を戻します。
wp/wp-config.phpの以下の行
define('WP_SITEURL', 'http://localhost:8888/wp');のURLをリモートの正しいURLに直します。
5)wp-adminにアクセス
wordpressのログインURLにアクセスします。
たとえば、
http://mydomain.com/wp/wp-admin/
など。
今迄のユーザー名とパスワードで入れるはずです。
ログインしたら、設定→一般タブから、サイトアドレス(URL)を確認。
ここをカスタマイズしている人は、リモートの環境にあわせて書き直します。
これで、バックアップしたサイトが完全にリストアできて、今迄と同じようにサイトが見えるはずです。
ROOT から matplotlib(pylab) + numpy へ(1次元&2次元ヒストグラム)
このエントリーは、ROOT一辺倒だった人間が時代の波に流されてしょーがないのでmatplotlib+numpyで図を書くのに「これどうすんの?!」と困った項目の備忘録です。何分初心者なので、ダサダサかつ間違ってるかも。
お品書き
- まとめ
- TH1D
- TCanvas
- pylab.hist? numpy.histogram?
- bin centerをとってくる
- Setlogy(), SetRangeUser()
- lineの幅などのデフォルト設定
- Legend
- Draw, gPad->Update()
- TH2D
- Contour
まとめ
高エネ・宇宙線業界でフツーに見る1次元ヒストグラムをpythonで書こう、というのが目標。
勿論、例題はいろいろ落ちているのだけど、どうも痒いところに手がとどかないというか……
若い人達がpylabで似たような絵を量産しているので、簡単にできるのだと思っていたら、dashiとかいう自前ライブラリーを使って書いていた。(ちなみに同名の公開モジュールがあるけど、そっちは別物)
大変便利そうだけど、きちんと公開されていない誰かのツールを使って絵を書くのは怖すぎるので断念。
で、そのdashiの中をみてみたのだけど、これが結構膨大なライブラリ群で、なんだ、ROOTと同じことするのにこんなに色々準備が必要なのか、と、すっかりpythonに完全移行する気は萎えてしまった(笑)。
というわけで、histogramを書いてprojectionとかガンガンやりたいけど、cintは使いたくない、というなら、大人しくPyROOTを使った方がいいんじゃないかという気がする。どうしてもmatplotlibっぽい絵にしたければ、rootplotあたり使うとか?(使ったことないけど)
しかし、まあ、せめてもっと自由に絵のお化粧くらいさせてくれ、と思ったので、とりあえずその方法のメモです。
(蛇足だが、matplotlibで描かれた絵がかなりの割合で軸が読みにくいのはなんとかならんか。プレゼンではほとんど見えない。セリフフォントは見た目綺麗だが、プレゼンにはむかないと思う。
若い人達、年寄りにもっと優しいフォント設定にしてくれ!
ROOTのデフォルト設定はHelbeticaだし、tickもラベルも割合大きめなので、手元で見ると無骨に見えちゃうんだけど、これは遠くからでも見やすいんだよ。)
TH1D
TH1Dでhist作って、Fillして…という流れは、matplotlibではどうなるか。
- fillするデータを配列もしくはnumpy.array()で準備。
- weightの値をデータと同じ次元の配列で用意。
- 最後にこれをpylab.histなどでプロット
といった手順になる。無骨にやると、for文でデータをひとつずつ読みながら、同時にweightも計算する、という感じになるのだけど、pythonだとこんな書き方もアリ。
(自分の練習プログラムをそのまま載せてるので、関係ない部分もいっぱいあるけどご容赦。最後の1行が該当部分。)
#!/usr/bin/python import numpy as np import matplotlib as mpl nevts1 = 10000 gammagen = 1 gammasig = 2 testflux = 1000 elog10low1 = 1 elog10high1 = 11 nbins1 = 20 # # util function for weight calculation # def weightfunc(eintg, elog10, nevts=1) : ene = 10.0**elog10 return eintg / (ene**(-gammagen)) * testflux * ene**(-gammasig) / nevts # # calculate integral of generation spectrum E^-(gammagen) # eintg1 = 0 if (gammagen == 1) : eintg1 = np.log((10**elog10high1)/(10**elog10low1)) else : eintg1 = ((10**elog10high1)**(1-gammagen) - (10**elog10low1)**(1-gammagen)) / (1-gammagen) # # prepare data with E^(-gammagen) # data1 = np.random.uniform(elog10low1, elog10high1, nevts1) # # calculate weights for data1. # use np.array so that we may scale the weights later! # flux1 = np.array([weightfunc(eintg1, ene) for ene in data1])
data1がデータ(入力値)の配列で、flux1がその重み(weight)。
計算したいweightが沢山ある場合は、forで回した方がいいかも。
numpy.array () or list ?
ところで、forで回しながらdataをappendするのに、numpyの配列を使うと必ず失敗するのだけど、何か根本的な使い方が間違っているのだろうか。
numpyは行列演算用の配列だからあとから行を増やすとかフツーはやらないのだと知った。。
pythonの配列は行列要素のスカラー倍演算すら受け付けてくれないので(まあ、そういう用途じゃないから当たり前か)、なるべくnumpy.arrayを使うようにしているのだけど、forで回しながらデータを追加するときは今のところしょうがないのでlistを使っている。
こんな感じ。
data1 = np.random.uniform(elog10low1, elog10high1, nevts1) flux1 = [] for i, ene in enumerate(data1) : flux1.append(weightfunc(eintg1, ene))
もっとも、追加じゃなくて、最初から配列のサイズが分かっている場合は、numpy.arrayを使って以下でもOK.
この方が、何度もメモリアロケートしないだけ早いかも。
data1 = np.random.uniform(elog10low1, elog10high1, nevts1) flux1 = np.zeros(len(data1)) for i, ene in enumerate(data1) : flux1[i] = weightfunc(eintg1, ene)
TCanvas
実は、matplotlibで一番よくわからんのが、matplotlibとpylabの違いだったりする。
matplotlib.pyplotに対して呼ばれる関数と、pylabに対して呼ばれる関数は何か違うのか? そこの使い分けはどうなってるの??
なんかpylabはインタラクティブインターフェース、、とか書いてあるんだけど、ドキュメントを読まずに例題をひろって無理矢理絵を描いているレベルではなんのこっちゃい。。。
というわけで、もうそこを理解するのは諦めて、とりあえずTCanvas相当のものが書ければいいや!ということで、例題。
2014/8/16 訂正
どうやらpylab.figureを使うと複数のfigureを開いた時に期待通りの動作をしてくれないことが分かったので、Pylab の代わりにmatplotlib.pyplot.figureを使うようにコードを変更。
#import Pylab as P import matplotlib.pyplot as plt # generate a canvas with an instance name "fig" # fig = P.figure() fig = plt.figure() # canvas->divide()? ax1 = fig.add_subplot(2,2,1) ax2 = fig.add_subplot(2,2,2) ax3 = fig.add_subplot(2,2,3) ax4 = fig.add_subplot(2,2,4)
plt.figure()がTCanvasの生成で、TCanvas::Divide(nx, ny)がadd_subplot(nx, ny, index).
ちょっと違うのは、add_subplotの三番目の引数が分割された窓のindexを表していて、戻り値にその窓への参照が返って来る、というところ。
TCanvasだと、canvas->cd(index) みたいなことをする必要があったのだけど、これは各パッドに名前がついてるから、いきなりそこに絵をかけて便利。
ちなみに、1枚しか要らない、という場合は、そもそもfigure関数を呼ぶ必要もないけど、そうするとその場合はy軸をlogにしたりy軸の範囲を制限したりするのに別の関数を使わないといけない(add_subplot →subplot, set_ylim →ylim、という感じで、どうも対応に一定のルールはあるようだけど)…という感じで混乱するので、面倒だから1枚だけのsubplotを作る、でいいと思う。
ax1 = fig.add_subplot(1,1,1)
このへんの統一感のなさが、matplotlibがとっつきにくい理由の一つのような気がするんだよなー。
公式ページの例題みても、同じ結果を得るのに違うやり方が多過ぎるよ。。。
2014/8/16追記:
どうやら、事情がのみこめてきた。
matplotlib.pyplotモジュールというのはとにかく何でも屋さんで、ユーザーがオブジェクト指向を気にせずに使えるようになっているらしい。
つまり、例題でよくあるplt.Plot(hoge)を呼ぶと、figure(TCanvas相当)を作って、subplotを作って、というのを勝手にやってくれて、それからhogeをDrowする、ということ。
一方、Pylab.figureはその背後で動いている関数なので、もっとC++ライクに、ちゃんとオブジェクトを作ってオブジェクトに対して関数を呼ぶ必要がある。
で、どうもPythonのインターフェース(この場合はmatplotlibだけど)には、クラス関数やメンバーのアクセスインターフェースを作る時の関数名のNaming Conventionがある模様。
つまり、Get関数、Set関数なんかは、インターフェースではGetやSetがおちて、その後ろだけでアクセスできるようになる。
だから、、set_ylim が matplotlib.pyplotではただのylimになってしまう、、と理解すると、いちいち二種類の関数を覚える必要はなくなるわけです。
(C++にどっぷり浸かった人間としては、折角カプセル化してprivateにして隠したデータメンバにset/getメソッドつけて、ってやってるのに、要するにこれってprivateメンバをpublicにしちゃうのと同じ??、、という抵抗感はあるのだが。。)
Colorbar
これで一件落着、と思ったら、2次元プロットのcolorbarを描くのに困ったことが発生。plotだとかhistだとか、2次元ヒストグラムのpcolorだとかはaxisに対して呼ぶことができるのだけど、その絵の横につけるcolorbarはaxisに対して呼ぶことが出来ず、plt.colorbar(ヒストグラム)、みたいな文法になる。
引数にヒストグラムオブジェクトをとっているのだから、そのヒストグラムの横に描いてくれるのかと思ったら、どうもそうではないらしい。
実は、matplotlibには、現在のfigure、現在のaxis、という概念がある。
つまりrootのgPadとまったく同じ概念で、どの絵のcolorbarでも現在のgPad(じゃないけど)の上に描いてしまうのだ。
まあ、実はcax=axisオブジェクト、とか引数を足してやれば、希望のaxisに描いてくれる(というか、多分もともと何処にcolorbarを描くかは至極自由に決められる仕様になっているということか)。…のだけど、この手動でaxisを決めてやるのが、結構めんどい。
ここに至り、どうやらPylab.figureを直接使うのは得策ではなくて、matplotlib.pyplot.figureを使うべきなのだと判明。
変えるのは、importのラインと、P.figure() の代わりにplt.figure()を呼ぶだけ。
こうやってfigureオブジェクトを作ってやれば、あとは関数名の方はset_ylimとかC++ライクな関数名が使えます。
canvas1->cd()?
で、どうやって問題のgPad (…じゃないけど)を移動するのか、という話ですが、こうするらしい。
ax1 = plt.subplot(2,2,1)
え、新しくsubplot作っちゃうんじゃないの、とか気になりますが、どうもこの関数は、その位置のsubplotが存在していなければ新しく作り、既にあったらそれをgPad(…じゃないけど…ってしつこい)にセットするものらしい。
ところで、この場合はまだfigureが1個(つまりTCanvasが1個)しかないから良いのだけれど、勿論複数のCanvasを描きたいことはある。
で、plt.figure()を4回くらい呼んで、それぞれfig1~fig4の変数名をつけたとする。で、一度fig4でお絵描きしてから、fig1に戻って来てcolorbarをつける、なんて場合には上の一行ではダメで、こうする。
#最初のfigureに移動。indexは0じゃなくて1であるのに注意。 fig1 = plt.figure(1) #fig1の1番目のaxisに移動 fig1ax1 = plt.subplot(2,2,1)
というわけで、rootなら canvas1->cd(1) の1行で済む作業が、matplotlibでは2行が必要になる、ということの模様。
ちなみに、indexが0からじゃなくて1から始まってるのは、rootのようにTCanvas自体が0番を指すから、じゃなくて、MATLABの伝統を受け継いでいるかららしい…。
pylab.hist? numpy.histogram?
さて、いよいよヒストグラムを書こう!
matplotlib,histと検索すると、pylab.histの例題が沢山ひっかかるのだけど、こいつがどうも使いにくい。
デフォルトでfillオプションになってヒストグラムを塗りつぶされちゃう。
オプションで histtype='step'をつければ、それっぽくはなるけど、今度は線の幅を指定できない。legendもなんか箱型になっちゃう。
というわけで、どうやら(高エネ・宇宙線業界で)フツーによく見るヒストグラムが書きたければ、numpy.histogramを使った方がよさそう。
まず、pylab.histの例題。
さっきdivideした窓の1番目(ax1)に書くことにする。
n, bins, patches = ax1.hist(data1, nbins1, weights=flux1/nevts1, histtype='step', color="magenta", label="pylab.hist") ax1.legend()
weightsのところで、配列flux1の要素を一律nevts1で割る、というのをやっているけど、これは先ほども書いたように、flux1がnp.arrayだから可能。
histtypeは'step'を指定しないと、デフォルトではfillされる。
絵を描くのにこれ1行で済んでしまうので、簡単といえば簡単なんだけど、このstepオプションの時の線幅や線種の変更の仕方がどうしても分からない。
というか、そもそもAPIドキュメントをみると、そういうオプションがないんだよね……。
というわけで、例題2。
np.histogramを使ってヒストグラムを生成→pylabでお絵描き。
yval, binEdges = np.histogram(data1, nbins1, weights=flux1/nevts1) ax2.step(binEdges[0:-1], yval, where='post', color="green", label="np step",linewidth=3) ax2.legend()
さっきつくった2番目の窓に描いてみました。
ポイントは、binEdgesはデータ数nに対してn+1個の要素数があるので、最後のデータを捨てること。
これだと、とりあえず線の太さは変えられるので、pylab.histよりはちょっとまし。
しかし、線の種類(破線にするとか)はどうも変えられないっぽいです(linestyle="dashed"を指定しても無視される)。
というわけで、次はダサダサだけど、データを変形してpylab.plotで書いちゃえ!という例題。
# # prepare data for plotting # def format (yval, binedges) : x = [] y = [] for index, value in enumerate(yval) : print "y = %f, binedge_low = %f, binedge_hi = %f" % (value, binedges[index],binedges[index+1]) x.append(binedges[index]) x.append(binedges[index+1]) y.append(value) y.append(value) # append very small value to close histos x.insert(0, x[0]) y.insert(0, 1e-30) x.append(x[-1]) y.append(1e-30) return x, y yval, binEdges = np.histogram(data1, nbins1, weights=flux1/nevts1) x, y = format(yval, binEdges) ax2.plot(x, y, '--', color="brown", label="numpy.histogram step",linewidth=1.5) ax2.legend()
もう完全にお絵描きのためのdirty fixです。これに使った配列で統計的な計算は何一つできません。
(まあ、オリジナルのhistogramが残ってるからいいんですが)
bin centerをとってくる
ヒストグラムのお絵描きにはあまり関係ないが、np.histogramは横軸の値としてbin_lowとbin_highを返してきて、binの中央値は戻ってこないので、bin centerを計算するときはどうするか。
この1行で済みます。このへんは確かにpython使いやすい。
bincenters = 0.5*(binEdges[1:]+binEdges[:-1])
Setlogy(), SetRangeUser()
ROOTでいえば、TAxisで設定するような項目です。
Y軸をlogにする方法はなんだか色々あって、もうどれを使っていいのやら、という感じなのだけど、ROOT風にやるなら、それぞれのパッドで指定できるのが有り難いので、subplotの各インスタンスの関数を使う。
ax3.set_yscale('log')
で、このlogyをやると、ヒストグラムの両端の縦棒が消えてしまうわけです……。なんだかな。
というわけで、無理矢理両端も閉じたかったら、やっぱりpylab.plotを使うしかないっぽい。
上のナンチャッテformat関数では、両端にy=1e-30なんて数字を埋め込んでいるので、このままではレンジが広過ぎてみにくいから、Y軸の範囲を制限します。
TAxisならSetRangeUserです。
ax3.set_ylim([1e-9, 1e3])
lineの幅などのデフォルト設定
いちいちlinewidthを指定するのが面倒な人は、この1行を書きます。
plt.rcParams['lines.linewidth'] = 2
デフォルトの線幅では、大抵細すぎて遠くからでは見えない。
線幅の他にも、いろいろ設定できるはず(多分…)。
Legend
Legendの指定も、ここではsubplotに対して行います。
これも、P.legend()みたいに呼べるんだけど、そうするとどの絵につけるのかが指定できないので。
ax4.legend()
Draw, gPad->Update()
絵を実際に表示するには、以下の一行が必要です。
plt.show()
これをスクリプトの途中で挟むと、そこでスクリプトが止まるっぽいので、最後にこの一行をおいて一気に描く。
例題を全部絵にすると、こんな感じです。
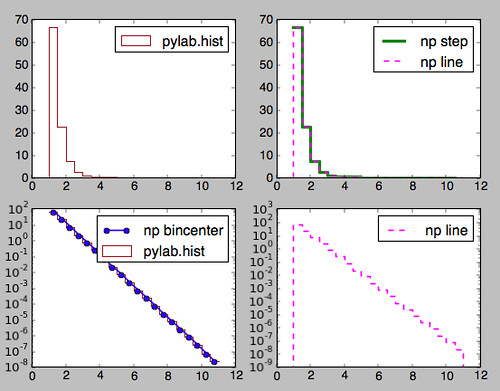
この絵を書いたスクリプトは以下の通り。debug printがそこかしこにありますが煩かったらコメントアウトして下さい。
#!/usr/bin/python import numpy as np import matplotlib.pyplot as plt # change default linewidth plt.rcParams['lines.linewidth'] = 2 nevts1 = 10000 gammagen = 1 gammasig = 2 testflux = 1000 elog10low1 = 1 elog10high1 = 11 nbins1 = 20 # # util function for weight calculation # def weightfunc(eintg, elog10, nevts=1) : ene = 10.0**elog10 return eintg / (ene**(-gammagen)) * testflux * ene**(-gammasig) / nevts # # calculate integral of generation spectrum E^-(gammagen) # eintg1 = 0 if (gammagen == 1) : eintg1 = np.log((10**elog10high1)/(10**elog10low1)) else : eintg1 = ((10**elog10high1)**(1-gammagen) - (10**elog10low1)**(1-gammagen)) / (1-gammagen) # # prepare data with E^(-gammagen) # data1 = np.random.uniform(elog10low1, elog10high1, nevts1) # # calculate fill weight for data1. # use np.array so that we may scale the weights later! # (python's list doesn't support even a scalar scale...) # flux1 = np.array([weightfunc(eintg1, ene) for ene in data1]) # # prepare drawing canvas (figure) # fig = plt.figure() # # option 1: use pylab # print "option 1" ax1 = fig.add_subplot(2,2,1) n, bins, patches = ax1.hist(data1, nbins1, weights=flux1/nevts1, histtype='step', color="brown", label="pylab.hist") ax1.legend() # draw same fig with log scale ax3 = fig.add_subplot(2,2,3) ax3.set_yscale('log') n, bins, patches = ax3.hist(data1, nbins1, weights=flux1/nevts1, histtype='step', color="brown", label="pylab.hist") # # option 2: use numpy.histogram # yval, binEdges = np.histogram(data1, nbins1, weights=flux1/nevts1) print "option 2" print yval print binEdges print binEdges[1:] print binEdges[:-1] # # use pylab.step # ax2 = fig.add_subplot(2,2,2) ax2.step(binEdges[0:-1], yval, where='post', color="green", label="np step",linestyle="dashed", linewidth=3) # # prepare data for line plotting # def format (yval, binedges) : x = [] y = [] for index, value in enumerate(yval) : print "y = %f, binedge_low = %f, binedge_hi = %f" % (value, binedges[index],binedges[index+1]) x.append(binedges[index]) x.append(binedges[index+1]) y.append(value) y.append(value) # append zeros to close histos x.insert(0, x[0]) y.insert(0, 1e-30) x.append(x[-1]) y.append(1e-30) return x, y x, y = format(yval, binEdges) print x print y ax2.plot(x, y, '--', color="magenta", label="np line",linewidth=1.5) ax2.legend() # show in log scale ax4 = fig.add_subplot(2,2,4) ax4.set_yscale('log') ax4.set_ylim([1e-9, 1e3]) ax4.plot(x, y, '--', color="magenta", label="np line",linewidth=1.5) ax4.legend() # # option 3: bin center # bincenters = 0.5*(binEdges[1:]+binEdges[:-1]) print "option 3" print bincenters ax3.plot(bincenters, yval,'o-', color="blue", label="np bincenter", linewidth=1.5) ax3.legend() plt.show()
TH2D
基本的に、np.arrayで1次元の代わりに2次元の配列を作れば良い。
import numpy as np
import matplotlib.pyplot as plt
n = 100
x = np.random.rand(n)
y = x + 0.5*np.random.normal(size=n)
# 1) forで回してfillする場合
nx = 3
ny = 6
xmin = 0.
xmax = 1.
dx = (xmax - xmin)/nx
ymin = -2.
ymax = 3.
dy = (ymax - ymin)/ny
hist1 = np.zeros((nx, ny))
for index, xvalue in enumerate(x) :
yvalue = y[index]
if xvalue < xmin or xvalue > xmax :
continue
if yvalue < ymin or yvalue > ymax :
continue
xi = int((xvalue - xmin)/dx)
yi = int((yvalue - ymin)/dy)
hist1[xi,yi] += 1.0
# 軸を用意。pcolor, pcolormesh関数はnx+1 x ny+1の二次元配列を
# それぞれxaxis, yaxisに指定しなくてはならない。
# 以下はたまにround offのせいかnx+2の要素数を返してくるのでダメ
# xaxis,yaxis = np.mgrid[slice(xmin, xmax+dx, dx), slice(ymin, ymax+dy, dy)]
xaxis,yaxis = np.mgrid[xmin:xmax:(nx+1)*1j, ymin:ymax:(ny+1)*1j]
print xaxis
print yaxis
print hist1
fig1 = plt.figure()
ax1 = fig1.add_subplot(1,2,1)
phist1 = ax1.pcolormesh(xaxis,yaxis,hist1)
#phist1 = ax1.pcolor(xaxis,yaxis,hist1)
plt.colorbar(phist1)
# 2) np.histogram2Dを使う
ax2 = fig1.add_subplot(1,2,2)
hist2, xedges, yedges = np.histogram2d(x, y, bins=(nx, ny), range=([xmin,xmax], [ymin,ymax]))
# 軸を用意。xedges, yedges は元々nx+1, ny+1の配列を返してくるので、
# これを2次元に変換。
# ただし、引数の順番に注意!!
yaxis2, xaxis2 = np.meshgrid(yedges, xedges)
print xaxis2
print yaxis2
print hist2
phist2 = ax2.pcolormesh(xaxis2, yaxis2, hist2)
#phist2 = ax2.pcolor(xaxis2, yaxis2, hist2)
plt.colorbar(phist2)
plt.show()
少々面倒な点は、軸の配列の用意。2次元の絵を書くのだから、軸は1次元かというとそうではなくて、軸も2次元で作ってやる必要がある。
しかも、i番目のデータはXi, Xi+1の区間にプロットされるので、軸は常にnx+1, ny+1個のデータが必要になる。
その方法として、np.mgridを使う方法と、np.meshgridを使う方法を挙げた。
mgridの方はまだ直感的に分かり易いのだけれど、[]の中身の指定の仕方がかなり特殊。
普通にslice(xmin, xmax+dx, dx)(xmin:xmax+dx:dxと同じ意味)とかやっちゃうと、dxが無理数の場合roundoff errorがでちゃって、nx+1個どころかnx+2になってしまい、pcolorで描こうとすると配列の次元が合わないと怒られる。
散々ネットで探した挙げ句、sliceの第三引数は通常stepサイズだけど、複素数で指定してやると分割数になることが分かった。
というわけで、分割数はnx+1になるので、それに複素数の1jをかけてやれば複素数で指定できる。
一方、meshgridではyaxis, xaxisの順に引数を指定してやり、戻り値もその順番で受け取らないと、何故か例題1)と同じにならない。
巷の例題では、結果の配列の方を上下左右入れ替える(np.rot90(hist2), np.flipud(hist2))としているものが多いのだけれど、そんな解決方法はイヤで、ちゃんとx軸は横に、y軸は縦に描いてほしいのである(笑)
というわけで、meshgridに食わせる引数と戻り値の順番の方を弄った方が良い、と思った次第。
ちなみに、pcolorとpcolormeshはほとんど同じことをやるのだけど、pcolormeshの方が早いらしい。(あと戻り値オブジェクトのクラスが違う)
そんなわけで、np.meshgridはなんか気持ち悪いのでずっとnp.mgridを使っていたのだけれど、np.mgridだとgridが固定幅で切られてしまう。gridの幅を自在に調節するにはやはりnp.meshgridを使うしかなさそう。詳しくは次の項目の例題で。
Contour
等高線プロットを書くには、こんな感じでよいらしい。
とりあえず、原点が (2.0 , 3.0) にある円の半径を等高線プロットにしてみる。
import numpy as np import matplotlib.pyplot as plt import sys def Func(x, y, ones = 1.0): # radius value of a circle with origin (2,3) z = np.sqrt((x - 2*ones)**2 + (y - 3*ones)**2) return z # Figure 1 : generate contor n = 20 xmin = 0 xmax = 3 # define x-values x = np.linspace(xmin, xmax, n+1) # define y-values, let's try non-linear binning. gamma = 2 y = x**gamma ymin = x[0]**gamma ymax = x[-1]**gamma # then, make grid. X, Y = np.meshgrid(x, y) # generate z-values from grids ONES = np.ones(x.shape) Z = Func(X, Y, ones=ONES) # plot contour. plt.figure(1) cont = plt.contour(X, Y, Z, levels=[0.5,1,2,3,4,5,6,7]) cont.clabel(fmt='%1.1f', fontsize=14) plt.title('simple contour generated from meshgrid') plt.grid() plt.savefig("fig1.png")
結果はこうなる。

ついでに、先の2次元ヒストグラムの例題で、np.meshgridの引数の順序を単純にx, y の順番に渡した場合の絵。
上のコードに続けて書く。
# Figure 2 : generate 2D hist. ngen = 100000 xvals = np.random.uniform(xmin, xmax, ngen) yvals = np.random.uniform(ymin, ymax, ngen) ones = np.ones(xvals.shape) weights = Func(xvals, yvals, ones=ones) # make histogram. hist, xedges, yedges = np.histogram2d(xvals, yvals, n, weights=weights, range=([xmin,xmax], [ymin,ymax])) # 2-1. Draw 2D hist with meshgrid plt.figure(2) XX, YY = np.meshgrid(xedges, yedges) phist = plt.pcolormesh(XX, YY, hist) plt.colorbar(phist) plt.title('histogram2d bad example') plt.savefig("fig2.png")
するとこんな感じで軸が上下左右反転してしまう。

正しくプロットするには、plt.pcolormeshの引数の順番を変更するか、meshgridの生成時に引数と戻り値の順番を変更する。こんな感じ。
# 2-2. Draw 2D hist with meshgrid, # order and return values and arguments are swapped plt.figure(3) YY, XX = np.meshgrid(yedges, xedges) phist = plt.pcolormesh(XX, YY, hist) plt.colorbar(phist) plt.title('histogram2d swapped') plt.savefig("fig3.png") plt.show()
これで予想通りのプロットになる。

WP-DBManager + MAMPでサイトのフルバックアップをとる方法
2014/1/23追記
最近は、サイトのファイル(wp-content直下)までバックアップしてくれるソフトとして、BackWPupというプラグインがあるらしい。しかも、バックアップファイルをDropBoxなど別のファイルサーバにも送ってくれるというスグレモノ。
BackWPUpは動かない率かなり高いです。なので、UpdraftPlus Backup/Restoreをおすすめします。
これは最初のセットアップさえ頑張ればかなり使いやすいです。
wp-content以下も保存してくれるし、DropBoxやGoogle Drive等にも自動保存できます。
詳細は「Wordpressの便利なバックアップ/リストアプラグイン - UpdraftPlus」をご覧下さい。
サイトにwpの機能を使って写真などを頻繁にアップロードする人は、こういったプラグインの使用をおすすめします。
サイトのフルバックアップはなかなか頭の痛い問題。
昔はhtmlだけだったから、単に全てのファイルをとってくれば済む話だったけれど、wordpressにしてから当然データベースのバックアップもとらないといけないわけで。
勿論、wordpressには、そのデータベースのバックアップをやってくれるプラグインがいくつかあります。
WP-DBManagerはデータベースファイルをメールで送ったりもしてくれるので、なかなか使い勝手が良いのだけど、ではこれをどうやって復元するの? と思ったときに、はたと困ってしまった。
ネットで検索すると、どこでも「新しいWPをインストールして…」という一文に突き当たります。これが嬉しくない。
理由は、山ほど入れているプラグインをまたダウンロードしてくるのが面倒臭い、というのもあるけど、もっと切実なのは、いつでも一番最新のWPやプラグインを使っているとは限らないからです。
まあ、wp本体はマイナーチェンジくらいでテーブルの構造が変わったりはしない、と信じたいけれど、サードパーティのプラグインあたりはバージョンが新しくなった時に新しくフィールドを足したり、といったことがあるかも知れない。
そうなると、いざサイトのファイルがぶっ壊れたときに、ぶっ壊れる直前のWP及びプラグインの、まったく同じバージョンのセットを作るのは大変だ、というのは容易に想像がつきます。
なので、できれば、定期的にWPフォルダごとバックアップして、一方でデータベースもWP-DBManagerで定期的にバックアップして、いざ事が起こったら、
1)データベースを完全消去
2)バックアップしたWPフォルダをコピー
3)WP-DBManagerのバックアップファイルを食わせて完全復帰!
という形にしたいわけです。
これができれば、現在使っているサーバが重くなったので、サーバを引っ越したい、というときにも簡単です。
で、こんな実験を今稼働しているサイトでやるのは危険すぎるので、とりあえずローカルでやってみよう、とMAMP環境の中でやってみたまとめ。
私がMacを使っているので、MacOSXを仮定していますが、基本的にはWindows + XMAMPでも同じはずです。
※ターミナルを使ってコマンド入力しますので、UNIXコマンドに慣れていない方にはちょっと敷居が高い方法かも。
MAMPのインストール
…は、よそさまのサイトでも沢山説明されているのでスキップ。
インストールができたら、/Applications/MAMP/htdocsの下に、サーバーからコピーしてきたwordpressフォルダを置きます。(私の場合このフォルダ名がwpとなっています)
MAMPのインストールの説明では、このあとwordpressをインストールして、wordpressからデータベースを作成する方法が書かれていることが多いですが、ここではデータベースへの接続は別の方法でやるので、その部分はスキップして下さい。
ユーザとデータベース作成
MAMPをインストールすると、デフォルトでmysqlにrootユーザが追加されます。でも、サーバー上でrootユーザで運営することなんてあるわけがないので、サーバー上で使っているデータベースのユーザ名とパスワードで新ユーザを作成します。
まずは、MAMPを起動しておいて、データベースにrootでログイン。
全てコマンドラインでやりますので、ターミナルを使います。
(ターミナルはアプリケーション/ユーティリティの中にあります。これをダブルクリックして起動します。)
ちなみに、mysqlコマンドは、MAMPの場合、/Applications/MAMP/Library/bin/mysql にあります。
MAMPのデフォルトrootパスワードはrootです。
以下、$記号はターミナル(デフォルトではbash)のプロンプト記号、mysql>はmysqlを起動した後のプロンプト記号です。
shellに詳しくない方は、行の最後でリターンキーを押すのを忘れずに。
$ /Applications/MAMP/Library/bin/mysql -u root -p
このあと、パスワードをきかれるので、rootと入れてリターン。
それから、以下のコマンドを打つ。
mysql> CREATE DATABASE データベース名;
mysql> GRANT ALL ON データベース名.* to ユーザ名@localhost;
mysql> FLUSH PRIVILEGES;
mysql> SET PASSWORD FOR ユーザ名@localhost=password('パスワード');文末の;も忘れずに打って下さい。
ここで必要な情報は全て、コピーしたwpフォルダの中の、wp-config.phpに書いてあります。
define('DB_NAME', 'test1'); // データベース名
define('DB_USER', 'test1'); // ユーザー名
define('DB_PASSWORD', '12345678'); // パスワードこんな感じ。
ところで、CREATE DATABASEで失敗することがあります。つまり、既にその名前のデータベースが存在している場合です。
その際は、作成するデータベースの名前を変えるか、必要なければ古いデータベースを以下のコマンドで消します。
ここでは、test1という名前のデータベースを、DROP DATABASEコマンドで削除します。
mysql> SHOW DATABASES; +--------------------+ | Database | +--------------------+ | information_schema | | test1 | | test2 | | test3 | | mysql | | performance_schema | +--------------------+ 6 rows in set (0.03 sec) mysql> DROP DATABASE test1; Query OK, 35 rows affected (6.11 sec) mysql> SHOW DATABASES; +--------------------+ | Database | +--------------------+ | information_schema | | test2 | | test3 | | mysql | | performance_schema | +--------------------+ 5 rows in set (0.03 sec)
こんな感じ。
テーブルが作れたら、一度mysqlを抜けます。
mysql> quit Bye
ここまでできたら、一気にDBにバックアップを流し込みます。WP-DBManagerでバックアップしたファイルを、仮にここではバックアップ.sqlとします。
$ /Applications/MAMP/Library/bin/mysql -u ユーザ名 -p データベース名 < バックアップ.sql
パスワードは、さっき指定したユーザ名のパスワードを入れて下さい。
できたら、早速接続確認!
ユーザ名とデータベース名は適宜変更。
$ /Applications/MAMP/Library/bin/mysql -u ユーザ名 -p mysql> USE データベース名 Database changed mysql> SHOW TABLES; +-------------------------------+ | Tables_in_test1 | +-------------------------------+ | wp_automaticSEOlinks | | wp_automaticSEOlinksStats | | wp_blc_filters | | wp_blc_instances | | wp_blc_links | | wp_blc_synch | | wp_commentmeta | | wp_comments | | wp_icl_cms_nav_cache | | wp_icl_content_status | | wp_icl_core_status | | wp_icl_flags | | wp_icl_languages | | wp_icl_languages_translations | | wp_icl_locale_map | | wp_icl_message_status | | wp_icl_node | | wp_icl_reminders | | wp_icl_string_positions | | wp_icl_string_status | | wp_icl_string_translations | | wp_icl_strings | | wp_icl_translate | | wp_icl_translate_job | | wp_icl_translation_status | | wp_icl_translations | | wp_links | | wp_options | | wp_postmeta | | wp_posts | | wp_term_relationships | | wp_term_taxonomy | | wp_terms | | wp_usermeta | | wp_users | +-------------------------------+ 35 rows in set (0.00 sec)
こんな感じで見えれば成功ではないでしょうか。
既存のwordpressへの接続
さて、ここまで済んだら、ローカルにコピーしてきたwordpressフォルダの中のwp-config.phpに1カ所だけ変更を加えます。
これをやらないと、ログインしようとしてもサーバ上のファイルにとんでしまいます。
/* wp-config.phpに以下の行を追加 */
define('WP_SITEURL', 'http://localhost:8888/wp');ちなみに、私のwordpressフォルダ名がwpなので、パスの最後がwpで終わっていますが、そこはご自身の環境に合わせて下さい。
これができたら、以下のアドレスにブラウザから接続します。
http://localhost:8888/wp/wp-admin/ (/wp/の部分は自分の環境に合わせる)
ユーザー名、パスワードとも、サーバで使っているもので接続できるはずです。
ログインしたら、設定→一般タブから、サイトアドレス(URL)を確認。
もとからここを弄っていない人は変更の必要はありませんが、ここをカスタマイズしている人は、ローカルの環境にあわせて書き直します。
これで、ローカルに完全なサイトのコピー作成完了!
ローカルでここまでやれれば、サイトのファイルがぶっとんだ時に、逆にローカルからサイトサーバへのコピーが簡単に作れます。
……といっても、使っているホスティングサーバがシェルによるログインをサポートしていて、内部でmysqlコマンドを使わせてくれることが前提条件ですが……(汗)。
この条件が満たされないサーバでは、もしかしたらmysqladminかなにかでmysqlの実行権限はもらえることもあるかもしれないので、それで頑張ってみて下さい。
ダメなら……やっぱりwordpressの新規インストールで頑張るしかないかな?(^^;)
楽譜を自費出版するには(オーケストラ)
オーケストラのフルスコア+パート譜の自費出版について、色々試行錯誤をしましたので、備忘録として残しておきます。
楽譜のダウンロード販売や、オンデマンド印刷について興味のある方は、以下の記事をご覧下さい。
「JASRAC管理曲の楽譜をダウンロード販売する(ついでに紙の楽譜もオンデマンド印刷)」
以下もくじ。
1)楽譜出版が可能な条件
2)JASRACへの手続き(作曲者がJASRAC会員の場合)
3)楽譜の浄書
4)印刷所の選定と経費
1)楽譜出版が可能な条件
言うまでもないことですが……
出版に関する全ての著作権を保持しているか、または全ての著作権者から出版の権利を認められている場合以外は、楽譜出版はできません。
歌詞付きの曲、編曲ものの場合は、著作権者が複数いる場合がありますので、ご注意を。
(実を言うと、著作権者がJASRAC会員である場合は、JASRACに使用料を払うことで、この問題はクリアされます。というのは、JASRAC会員はその許可を出す権利をJASRACに信託しており、JASRACは「この相手には許可を出したくない」といった例外を認めないからです。ポピュラーミュージックの器楽編曲楽譜の出版、とくに個人でやっているオンライン出版などは、原曲作曲者に連絡をとらずにJASRACに使用料を支払うだけ、というケースが多いと思います。
しかし、歌詞の方はJASRACと契約していない方も多いので、注意が必要です。器楽編曲で歌詞はいらない、という場合でも、著作権は作詞者と作曲者の共同権利になっていますので、双方の許可を得る必要があります。)
2)JASRAC等への手続き(作曲者がJASRAC会員の場合)
JASRAC会員の方は、自分の楽曲を自分で使用する(この場合出版する)場合でも、楽譜販売で利益が出る場合は著作権使用料を支払う必要があります。
自分のものを使って何故使用料が必要なのか、と思われるかもしれませんが、JASRACの場合は信託契約ですので、著作権使用料の業務を「委託」しているのではなく、著作権使用料を徴収する権利そのものを「信託」しているため、このような形になります。
勿論、支払った使用料は、JASRACの手数料を差し引いた後に使用料分配の形で戻ってきます(使用楽曲に共同権利者がいる場合は、そちらにも分配されます)。
以前は、著作権使用料を支払うと、認可番号入りのJASRACシールが送られてきて、それを楽譜に添付して売ること、となっていました。
しかし、近年このJASRACシールが廃止され、印刷物に直接認可番号を印刷するように変更されました。
というわけで、目当ての楽譜を印刷する前に、発行部数と定価を決めてJASRACに届けて認可番号をもらう必要があります。
認可番号自体は申請すれば割合に早く出してもらえますので、印刷所に見積もりをとり、定価を設定した後すぐにJASRACに届けて認可番号をもらい、印刷する楽譜の原稿の奥付部分に指定の書式で認可番号を書き込んでから入稿すれば良いと思います。
一方、楽譜販売で利益が出ない場合、つまり、自分の楽曲を広めるため、プロモーションの目的で楽譜を作成したい、といった場合には、一定の条件を満たすと、JASRACの「自己使用規定」の適用が受けられる場合があります。2013年現在、その条件は以下の通りです。
- 当該著作物の利用の開発を目的とした使用であること(「PROMOTION ONLY」「プロモーション用」などと表示する)
- 日本国内における使用であること
- 使用の都度、使用の1週間前までに所定の書式によりJASRAC担当部署に届け出ること
- 当該著作物に係る全ての関係権利者(音楽出版者を含む)の、所定の書式による同意書を提出すること
- 発行者が委託者本人であること(委託者本人と同一視し得る親族または個人事務所等を含む)
- 著作物の提示につき対価を得ないこと(ただし製作費等の実費相当の対価は対価とみなさない)
- 同一の使用の中で、自己の著作物以外の著作物を使用する場合は、当該著作物の使用について、別途当協会(JASRAC)の許諾を得ること
2018.4.28 追記:
JASRACの自己使用規定が変更されました。条件付きで利益が出る商品でも自己使用が認められるそうです(部数などに制限あり)。
ただし、そのかわりに、オンラインでの公開にも期間やダウンロード数などの制限がつきました。
くわしくはJASRACにお尋ねください。
いずれにしても、JASRACに届出が必要という部分は変わりませんので、早めにJASRACの担当部署に相談するのが良いと思います。
3)楽譜の浄書
最近はコンピュータで楽譜を書く方が増えているので、曲が出来たときにはスコアとパート譜も出来ている、といったケースが多いと思いますが、手書き派の方はここで浄書屋さんに版下となる楽譜を作ってもらうことになります。
10分のオケ譜でいくらになるかは……頼んだことないのでわかりません(^^;)。
楽譜の浄書というと、あまり普段は意識されない作業ですが、実はとても大事です。
楽譜というのは、演奏中に短時間で視線を走らせて読み取るものです。演奏家は、音符の一つ一つを真面目にじっくり見るのではなくて、現在演奏している数小節前をざっくり眺めて、頭に叩き込んで演奏します(でないと間に合いませんから!)。
それでいて、間違うことは許されないのですから、非常に高度かつ精密な作業を短時間で行っているわけです。
楽譜は、そういったハードタスクをこなしている演奏家にとって、可能な限り読み易いように作られている必要があります。素人がかいた楽譜が非常に読みにくいのは、そういった配慮がなされていないからです。
Finaleなどの楽譜ソフトも、今でこそ、それほど違和感を感じないレベルの楽譜を作るようになりましたが、最初は惨惨たるもので、付点音符がやたら間延びしていて見にくかったり、十六分音符のつまり方が十分でなくつい八分音符で演奏したくなってしまうような楽譜だったり、と色々ありました。
現在のFinaleでも、プロの浄書屋さんや、まともな楽譜出版社の編集の目からすれば、とてもそのまま商品にできるシロモノではない、と仰ると思います。昔は音符ひとつひとつをハンコで押して浄書していた楽譜も、流石に現在ではコンピューター浄書が主流になっていますが、それでもプロの方々は記号の場所や音符の間隔、指示記号の付け方など、最新の注意を払って微調整を繰り返しています。
こういった作業を外注すれば、勿論それなりのコストがかかりますが、本当に美しい楽譜を作りたい方は、検討する価値があるかもしれません。
まあ、とりあえず不都合なく読めればいいや、という方や、微調整は自分でやります、という方は、印刷会社にどのようなものを選ぶかによって、最終原稿の形が決まります。
多くの場合は、今の御時世、多分PDFファイルでOKだと思いますが。
(ただし、フォントが全部埋め込まれている必要があります。殆どのソフトはデフォルトでそうなりますが、フリーのpdf作成ソフトなどを使うと怪しい場合もあります。)
ちなみに、浄書屋さんのファイルはイラストレータ書類だったりすることもあるみたいです。音符や記号の位置を微調整したいなら、たしかにその方が便利でしょう。まさにアートの粋!
4)印刷所の選定と経費
さて、印刷をどうするか、というのは、個人出版を考えるときには最大の焦点だと思います。
まず、大手音楽出版社が使うような印刷会社は、よほど資金が潤沢にないと無理でしょう。(というか、そもそも個人相手では取引してくれないかも。)
というわけで、電子出版を考えるのでない限りは、自費出版を請け負ってくれる、比較的小さな印刷会社に完全原稿を持ち込む、という形になると思います。
幸いなことに、日本は自費出版文化が盛んなため、このタイプの印刷会社は非常に沢山あります。
まあ、ホームページを見ると、ゲームやアニメーションのキャラクターが溢れていたりしてビビるようなケースもあるかもしれませんが……
(こういった会社でも漫画原稿以外の印刷もやってますので、大丈夫です。むしろ、細かい線の印刷に慣れているので、楽譜も上手く印刷してくれるかも。)
さて、こういった印刷会社に頼む場合に注意すべき点がいくつかあります。
まず、印刷会社によっては、一般印刷と同人印刷の二種類の受付をしているところがあります。この場合、一般印刷扱いで発注するか、同人印刷枠で発注するかで値段が2倍〜3倍くらい変わります。同人印刷が安いのには理由がありますので、そのあたりを細かく印刷屋さんに説明して頂いた上で、どちらにするか決めるのが良いと思います。
印刷屋によって異なりますが、よくある一般的な違いは、同人印刷の場合は版に少部数印刷用のものを使っている(通称ピンク版と呼ばれる紙版)、紙の目を気にしない(紙にも布地のように方向があるのです)、といった感じです。
特に、数百部までの少部数発行の場合、版の違いはコストに大きく響きます。
もう一点、非常に大事なのは、印刷の品質です。
こればかりは、その印刷会社で印刷されたものを見て判断するしかありません。
高価な版を使えば印刷品質が良くなるのは一般論としてそうですが、実は、印刷会社の腕とこだわりが最も強く出る部分でもあります。
「うちは綺麗な印刷に命をかけています!」という印刷会社もあれば、「納期2日でオフセット印刷可能!」というような納期で勝負の会社もあります。
ことに、楽譜を印刷する場合、後者よりは前者の方が適しているのは間違いありません。
縮小されたフルスコアなどの場合、細いスラーやテヌート、スタッカートの点などを綺麗に出せるか?
逆に、へんなゴミ点が入って、四分音符が付点四分音符になってしまうような危険はないか?
具体的に原寸の原稿を印刷会社に持ち込み(あるいはデータで送り)、この線は出ますか? といった相談は是非すべきです。
一般論として、0.2ポイント以下の線は保証しない、というのが軽印刷の場合の基準です。
残念ながら、フルスコアをA4で印刷するような場合、これよりも細い線だらけ、というのが実情だと思います。
しかし、中には0.2ポイント以下の、途切れそうな細い線でも綺麗に出してくれる印刷所もあります
(同じページにベタやインクの濃い部分があると無理ですが、楽譜印刷の場合そういったケースはないと仮定して)。
一方、ピアノ譜や楽器のソロ譜などはそんなに細い線はないでしょうから、そこまで印刷品質に神経質になる必要はないかも知れません。
印刷を綺麗に出すには、紙を選ぶことも重要です。
印刷会社には色々な本文用紙がありますが、線を綺麗に出したい場合には、上質紙が一番良いとのことです。(クリーム色の紙がいい人は淡クリームキンマリもおすすめ)
上質紙は厚さ(重さ)のバリエーションも色々ありますが、70kgでは楽譜が裏映りして見にくいので、我々は90kgを使いました。
原稿については、最近はpdfなどのデジタルデータでの入稿をサポートしているところが多くなっていますが、印刷された紙の原稿しか受け付けないところもあります。その場合は、所定の書式に従って紙の原稿を用意する必要があります。
なお、蛇足ですが、殆どの町の印刷会社では、A3の中綴じ製本は出来ません。(無線綴じは可)
これは印刷機のサイズの限界がA3のことが多く、A3中綴じの本を作るにはA2サイズの印刷が出来なければならないからです。
というわけで、指揮者用スコアを中綴じで作るのは大変難しくなります。
無線綴じは90度以上のヒラキに弱いため、指揮用スコアのように180度広げて使用するようなケースでは、まず間違いなくページ抜けが起こります。
我々も、色々検討しましたが、手持ちの予算内ではよい解決法がみつからず、結局指揮用スコアの自費出版は断念しました。
さて、ある意味スコアの印刷は冊子ですので、そう難しくはないのですが……。
問題は、パート譜です。
パート譜も全て印刷譜で提供する場合、1セットで演奏が可能になるよう、弦パートは多めに印刷するなど、部数を調整しなくてはなりません。
パート毎に別々に印刷する必要があるのは勿論、紙も、譜面台に立てて使えるよう、ある程度厚いものにする必要があります。
上質紙だと90kgでは多分倒れてくるので、110kg以上、という感じになると思います。当然、分厚い方が紙の単価は上がります。
(バイオリン譜などページ数が多く、中綴じにする場合は90kgでも良いでしょうが)
また、大抵のパート譜は見開きになるので、「面付け」と言われる作業も必要です。
(面付けの方法がわからなければ、市販の楽譜を見本として持っていき、どんな原稿を作れば良いか、印刷会社に尋ねる)
特に、フル編成のオーケストラとなると、こういったパート譜を20種類程度(あるいはもっと多く)作ることになります。
というわけで、ほとんどの場合、フルスコアよりもパート譜の印刷でかなり手間もコストがかさむと思います。
実は、我々も最初は紙のパート譜を付けるつもりで試算をしたのですが、それでは予算を大幅に超えてしまうこと、また印刷された楽譜の保存スペースもばかにならないことから、結局パート譜はプレスCDに収めたPDFファイルで提供する方針に変更しました。
最近は、CDプレスもかなり値段が抑えられてきています。
また、CDから直接プリントする分には、プリントできる枚数に制限がありませんので、弦パートが足りない、などの問題が起こりません。
難点は、楽譜を購入される方がCDドライブ付きのコンピュータを持っていること及び、プリンタを所持していることが条件になることですが、これに関しては、その環境がない方向けに個別にプリントサービスをする等で対応する予定です。
これをもっと推し進めて、いっそフルスコアも同じCD(またはDVD)に収めてしまう、という考え方も出来ます。
この方法ですと、ジャケット代全部含めても5万円以下で100部程度の楽譜出版が可能になります。
(ただし、この場合、全てがデジタルデータになっていることから、オリジナルとコピーの区別がつかないため、違法コピーを取り締まることは実質ほぼ不可能になると思われます。……といっても、現状、紙媒体の違法コピーも殆ど野放しですが。)
JASRACに問い合わせたところ、パート譜のみCDに収録してスコアに添付、といった場合には、CD中に含まれるものが楽譜のみである限りは、著作権使用料は紙の楽譜と同様に計算されるとのことです。
ただし、どうせCDに収めるなら、サンプル音源も一緒に、ということになりますと、音源の部分には別途録音物に対する著作権使用料がかかりますのでご注意下さい。
販売楽譜は、基本的に本当に薄い利益しか出ません。
(自費出版で経費を極限まで抑えても、です! なにしろ、よっぽどのヒット曲でない限り、たった100部売り切るのだって、何年もかかりますから……)
しかし、演奏者側から見れば、レンタル楽譜よりもずっと手に取りやすいこともあり、沢山の方に曲を知ってもらうには良い方法です。
自費出版の良いところは、万が一たった1部も売れなくても(!)損失が限定されている、という点です。
曲の長さや編成、印刷所の選び方によっては、国内旅行1回分くらいの経費で出版出来ます。
最近はFinaleなどで作曲していて、プロの浄書に頼まなくても、そこそこ見栄えの良い楽譜が作成出来る方も多いと思います。
出版社から楽譜を出版するのは無理でも、楽譜を自費出版してみたい、という方の助けになれば、と思い、こんなエントリーを書いてみました。
レンタル楽譜の契約で知っておくべきこと
レンタル楽譜の契約、といっても、借りる人のことではありません。
作曲家が、音楽出版社と契約を結び、レンタル楽譜用に楽曲を提供する場合の話です。
もっといえば、作曲家、音楽出版社とも、JASRACの会員であることを仮定しています。
ちなみに、以下の話は2013年8月現在の話です。
この場合、契約によって、次のような事態が起こり得ます。
- この契約により、当該楽曲(レンタル楽譜になる楽曲)は、音楽出版社も共同権利者になります。具体的には、著作権使用料(この楽曲の演奏による演奏使用料、録音使用料など)の分配の際には、音楽出版社と折半になります。(音楽出版社との契約内容によるかも知れません)
- JASRACでは、同じ楽曲の異なる編成(たとえばピアノ版と吹奏楽編曲版など)を異なったレコードとはみなしません。また、改訂版か否かの差もありません。申請のタイミングで別IDが振られる事はありますが、基本的に同一の曲として扱われますので、そのうちのどれかの共同権利者リストが変更になった場合には、変更は全ての関連レコードに及びます。
どういうことか、実際に例を上げてみると……
たとえば、吹奏楽版はレンタル楽譜でA音楽出版社に取り扱ってもらい、ピアノ版はB音楽出版社に出版してもらった、とかいうような場合。
まず、B音楽出版社がJASRACに収めた楽譜出版時の著作権使用料が、半分はA音楽出版社に分配されます。
また、ピアノ版が演奏された場合の演奏使用料も、半分がA音楽出版社に分配されます。
A音楽出版社が、まったくピアノ版のプロモーションに関わっていなくとも、です。
共同権利者というのは、文字通り、著作者の全ての権利を折半する相手なわけです。
JASRACが別編曲を別レコード扱いにしてくれれば話は簡単なので、是非そうしてくれと交渉してみたのですが、逆にそうすることによって分配漏れの恐れがある、という理由で却下されました。
もっといえば、JASRACは「著作権管理団体」であって、編曲についてはどちらかといえば「原曲作曲者と相談の上そちらで決めて下さい」といった感じですので、そもそも編曲を単一レコード扱いする仕組みになっていないのかもしれません。
(既に原曲作曲者の権利が消滅した楽曲の編曲については、年4回行われるJASRAC規定の審査に通ったものだけが採用されます。この場合のレコードの取扱は、一般の作曲した楽曲と同じです)
楽譜出版の場合は、むしろ音楽出版社が作曲者に著作権使用料を払って楽譜を印刷し、共同権利者にもならない、というケースが多いので、このような問題は起こりにくいのですが、レンタル楽譜の場合は注意が必要です。
1曲につき、編成はいつも一通りしかない、という方は特に問題にならないと思いますが、同じ曲で編成違いの編曲が多くある方は、レンタル楽譜の場合、こういった事態もあり得ると念頭に置いて契約された方がよろしいかと思います。